Hein Putter and Hans van Houwelingen have a new paper in Statistical Methods in Medical Research. This reviews the use of frailties within multi-state models, concentrating on the case of models observed up to right-censoring and primarily looking at models where the semi-Markov (Markov renewal) assumption is made. The paper clarifies some potential confusion over when frailty models are identifiable. For instance, for simple survival data with no covariates, if a non-parametric form is taken for the hazard then no frailty distribution is identifiable. A similar situation is true for competing risks data. Things begin to improve once we can observe multiple events for each patient (e.g. in illness-death models), although clearly if the baseline hazard is non-parametric, some parametric assumptions will be required for the frailty distribution. When covariates are present in the model, the frailty term has a dual role of modelling dependence between transition times but also soaking up lack of fit in the covariate (e.g. proportional hazards) model.
The authors consider two main approaches to fitting a frailty; assuming a shared Gamma frailty which acts as a multiplier on all the intensities of the multi-state model and a two-point mixture frailty, where there are two mixture components with a corresponding set of multiplier terms for the intensities for each component. Both approaches admit a closed form expression for the marginal transition intensities and so are reasonably straightforward to fit, but the mixture approach has the advantage of permitting a greater range of dependencies, e.g. it can allow negative as well as positive correlations between sojourn times.
In the data example the authors consider the predictive power (via K-fold cross-validation) of a series of models on a forward (progressive) multi-state model. In particular they compare models which allow sojourn times in later states to depend on the time to first event, with frailty models and find the frailty model performs a little better. Essentially, these two models do the same thing and as the authors note, a more flexible model for the effect of time of first event on the second sojourn time may well give a better fit than the frailty model.
Use of frailties in models with truly recurrent events seems relatively uncontroversial. However for models where few intermediate events are possible their use, rather than some non-homogeneous model allowing dependence both on time since entry to the state and time since initiation, the choice is largely related to either what is more interpretable in terms of the application at hand or possibly what is more computationally convenient.
Monday, 28 November 2011
Sunday, 20 November 2011
Isotonic estimation of survival under a misattribution of cause of death
Jinkyung Ha and Alexander Tsodikov have a new paper in Lifetime Data Analysis. This considers the problem of estimation of the cause specific hazard of death from a particular cause in the presence of competing risks and misattribution of cause of death. They assume they have right-censored data for which there is an associated cause of death, but that there is some known probability r(t) of misattributing the cause of death from a general cause to a specific cause (in this case pancreatic cancer) at time t.
The authors consider four estimators for the true underlying cause-specific hazards. Firstly they consider a naive estimator which obtains Nelson-Aalen estimates of the observed CSHs and transforms them to true hazards by solving the implied equations
 &=& r(t)d\Lambda_{2}(t) + d\Lambda_{1}(t)\\ d\hat{\Lambda}^{Obs}_{2}(t) &=& (1-r(t))d\Lambda_{2}(t)\\ \end{matrix} "\begin{matrix} d\hat{\Lambda}^{Obs}_{1}(t) &=& r(t)d\Lambda_{2}(t) + d\Lambda_{1}(t)\\ d\hat{\Lambda}^{Obs}_{2}(t) &=& (1-r(t))d\Lambda_{2}(t)\\ \end{matrix}")
This estimator is unbiased but has the drawback that there are negative increments to the cause-specific hazards.
The second approach is to apply a (constrained) NPMLE estimate for instance via an EM algorithm. The authors show that, unless the process is in discrete time (such that the number of failures at a specific time point increases as the sample size increases), this estimator is asymptotically biased.
The third and fourth approaches take the naive estimates and apply post-hoc algorithms to ensure monotonicity of the cumulative hazards, by using the maximum observed naive cumulative hazard up to time t (sup-estimator) or by applying the pool-adjacent-violators algorithm to the naive cumulative hazard. These estimators have the advantage of being both consistent and guaranteed to be monotonic.
The authors consider four estimators for the true underlying cause-specific hazards. Firstly they consider a naive estimator which obtains Nelson-Aalen estimates of the observed CSHs and transforms them to true hazards by solving the implied equations
This estimator is unbiased but has the drawback that there are negative increments to the cause-specific hazards.
The second approach is to apply a (constrained) NPMLE estimate for instance via an EM algorithm. The authors show that, unless the process is in discrete time (such that the number of failures at a specific time point increases as the sample size increases), this estimator is asymptotically biased.
The third and fourth approaches take the naive estimates and apply post-hoc algorithms to ensure monotonicity of the cumulative hazards, by using the maximum observed naive cumulative hazard up to time t (sup-estimator) or by applying the pool-adjacent-violators algorithm to the naive cumulative hazard. These estimators have the advantage of being both consistent and guaranteed to be monotonic.
Monday, 14 November 2011
Likelihood based inference for current status data on a grid
Runlong Tang, Moulinath Banerjee and Michael Kosorok have a new paper in the Annals of Statistics. This considers the problem of non-parametric inference for current status data when the set of observation times is a grid of points such that multiple individuals can have the same observation time. This is distinct from the scenario usually considered in the literature where the observation times are generated from a continuous distribution, such that the unique number of observation times, K, is equal to the number of subjects, n. In this case, non-standard (Chernoff) asymptotics with a convergence rate of  applies. A straightforward alternative situation is where the total number of possible observation times has a fixed K. Here, standard Normal
applies. A straightforward alternative situation is where the total number of possible observation times has a fixed K. Here, standard Normal  asymptotics apply as n tends to infinity (though n may need to be much larger than K for approximations based on this to have much practical validity).
asymptotics apply as n tends to infinity (though n may need to be much larger than K for approximations based on this to have much practical validity).
The authors consider a middle situation where K is allowed to increase with n at rate . They show that provided
. They show that provided  , standard asymptotics apply, whereas when
, standard asymptotics apply, whereas when  , the asymptotics of the continuous observation scheme prevail. Essentially for , the NPMLE at each grid time point tends to its naive estimator (i.e. the proportion of failures at that time among those subjects observed there) and the isotonization has no influence. Whereas for there will continue to be observation times sufficiently "close" but distinct such that the isotonization will have an effect. A special boundary case applies when
, the asymptotics of the continuous observation scheme prevail. Essentially for , the NPMLE at each grid time point tends to its naive estimator (i.e. the proportion of failures at that time among those subjects observed there) and the isotonization has no influence. Whereas for there will continue to be observation times sufficiently "close" but distinct such that the isotonization will have an effect. A special boundary case applies when  , with an asymptotic distribution depending on c where c determines the spacing between grid points via
, with an asymptotic distribution depending on c where c determines the spacing between grid points via  .
.
Having established these facts, the authors then develop an adaptive inference method for estimating F at a fixed point. They suggest a simple estimator for c, based on the assumption that . The estimator has the property that c will tend to 0 if and tend to infinity if . Concurrently, it can be shown that the limiting distribution for the case tends to the standard normal distribution as c tends to infinity and tends to the Chernoff distribution when c goes to 0. As a consequence, constructing confidence intervals by assuming the asymptotics but with c estimated, will give valid asymptotic confidence intervals regardless of the true value of
. The estimator has the property that c will tend to 0 if and tend to infinity if . Concurrently, it can be shown that the limiting distribution for the case tends to the standard normal distribution as c tends to infinity and tends to the Chernoff distribution when c goes to 0. As a consequence, constructing confidence intervals by assuming the asymptotics but with c estimated, will give valid asymptotic confidence intervals regardless of the true value of  .
.
There are some practical difficulties with the approach as the error distribution of the NPMLE of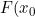 "\inline F(x_{0})") depends both on and the sampling distribution density
depends both on and the sampling distribution density 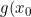 "\inline g(x_{0})") as well as c. Moreover, whereas for , there is scaling invariance such that one can express the errors in terms of a function of an indexable distribution (i.e. the Chernoff distribution). The boundary distribution for does not admit such scaling so would require bespoke simulations to establish for each case.
as well as c. Moreover, whereas for , there is scaling invariance such that one can express the errors in terms of a function of an indexable distribution (i.e. the Chernoff distribution). The boundary distribution for does not admit such scaling so would require bespoke simulations to establish for each case.
The authors consider a middle situation where K is allowed to increase with n at rate
Having established these facts, the authors then develop an adaptive inference method for estimating F at a fixed point. They suggest a simple estimator for c, based on the assumption that
There are some practical difficulties with the approach as the error distribution of the NPMLE of
Bayesian inference for an illness-death model for stroke with cognition as a latent time-dependent risk factor
Van den Hout, Fox and Klein Entink have a new paper in Statistical Methods in Medical Research. This looks at joint modelling of cognition data measured through the Mini-Mental State Examination (MMSE) and stroke/survival data modelled as a three-state illness-death model. The MMSE produces item response type data and the longitudinal aspects are modelled through a latent growth model (with random slope and intercept). The three-state multi-state model is Markov conditional on the latent cognitive function. Time non-homogeneity is accounted for in a somewhat crude manner by pretending that age and cognitive function vary with time in a step-wise fashion.
The IRT model for MMSE allows the full information from the item response data to be used (e.g. rather than summing responses to individual questions to get a score). Similarly, compared to treating MMSE as an external time dependent covariate, the current model allows prediction of the joint trajectory of stroke and cognition. However, the usefulness of these predictions are constrained by how realistic the model actually is. The authors make the bold claim that the fact that a stroke will cause a decrease in cognition (which is not explicitly accounted for in their model) does not invalidate their model. It is difficult to see how this can be the case. The model constrains the decline in cognitive function to be linear (with patient specific random slope and intercept). If it actually falls through a one-off jump, then the model will still try to fit a straight line to a patient's cognition scores. Thus the cognition before the drop will tend to be down-weighted. It is therefore quite feasible that the result that lower cognition causes strokes is mostly spurious. One possible way of accommodating the likely effect of a stroke on cognition would be to allow stroke status to be a covariate in the linear growth model e.g. for multi-state process "\inline X(t)") and latent trait
and latent trait  "\inline \theta(t)") , we would take
, we would take
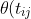 = \beta_0 + \beta_1 t_{ij} + \beta_2 I(X(t_{ij})=2) "\theta(t_{ij}) = \beta_0 + \beta_1 t_{ij} + \beta_2 I(X(t_{ij})=2)")
where the may be correlated random effects.
may be correlated random effects.
The IRT model for MMSE allows the full information from the item response data to be used (e.g. rather than summing responses to individual questions to get a score). Similarly, compared to treating MMSE as an external time dependent covariate, the current model allows prediction of the joint trajectory of stroke and cognition. However, the usefulness of these predictions are constrained by how realistic the model actually is. The authors make the bold claim that the fact that a stroke will cause a decrease in cognition (which is not explicitly accounted for in their model) does not invalidate their model. It is difficult to see how this can be the case. The model constrains the decline in cognitive function to be linear (with patient specific random slope and intercept). If it actually falls through a one-off jump, then the model will still try to fit a straight line to a patient's cognition scores. Thus the cognition before the drop will tend to be down-weighted. It is therefore quite feasible that the result that lower cognition causes strokes is mostly spurious. One possible way of accommodating the likely effect of a stroke on cognition would be to allow stroke status to be a covariate in the linear growth model e.g. for multi-state process
where the
Thursday, 3 November 2011
Relative survival multistate Markov model
Ella Huszti, Michal Abrahamowicz, Ahmadou Alioum, Christine Binquet and Catherine Quantin have a new paper in Statistics in Medicine. This develops a illness-death Markov model with piecewise constant intensities in order to fit a relative survival model. Such models seek to compare the mortality rates from disease states with those in the general population, so that the hazard from state r to absorbing state D are given by
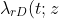 = \lambda_{\mbox{pop}}(t ; z) + \lambda^{*}_{rD}(t)\exp(\beta_{rD} z) "\lambda_{rD}(t ; z) = \lambda_{\mbox{pop}}(t ; z) + \lambda^{*}_{rD}(t)\exp(\beta_{rD} z)")
The population hazard is generally assumed known and taken from external sources like life tables. Transition intensities between transient states in the Markov model are not subject to any such restrictions. One can think this as being a model where there is an unobservable cause of death state "death from natural causes" which has the same transition intensity regardless of the current transient state.
The paper has quite a lot of simulation results, most of which seem unnecessary. They simulate data from the relative survival model and show, unsurprisingly, that a misspecified model that assumes proportionality with respect to the whole hazard (rather than the excess hazard) is biased. They also compare the results with Cox regression models (on each transition intensity) and Lunn-McNeil competing risks model (i.e. assuming a Cox model assuming common baseline for the competing risks).
The data are a mixture of clinic visits that yield interval censored times of events such as recurrence, but times of death are known exactly. Presumably for the Cox models a further approximation of interval-censored to right-censored data is made.
The population hazard is generally assumed known and taken from external sources like life tables. Transition intensities between transient states in the Markov model are not subject to any such restrictions. One can think this as being a model where there is an unobservable cause of death state "death from natural causes" which has the same transition intensity regardless of the current transient state.
The paper has quite a lot of simulation results, most of which seem unnecessary. They simulate data from the relative survival model and show, unsurprisingly, that a misspecified model that assumes proportionality with respect to the whole hazard (rather than the excess hazard) is biased. They also compare the results with Cox regression models (on each transition intensity) and Lunn-McNeil competing risks model (i.e. assuming a Cox model assuming common baseline for the competing risks).
The data are a mixture of clinic visits that yield interval censored times of events such as recurrence, but times of death are known exactly. Presumably for the Cox models a further approximation of interval-censored to right-censored data is made.
Subscribe to:
Comments (Atom)